Personality prediction by social media using Natural Language Processing
Today the world is witnessing exponential growth in the number of people using social media platforms. People use these platforms to express themselves by sharing their thoughts, feelings, emotions, experiences, and a lot of other information. This information can be very useful to understand a user which indeed is helpful to plan marketing strategy according to the user’s personality. Personality is a psychological construct accounting for different individuals. Personality Prediction has gained a lot of attention nowadays as it studies the behavior of users and reflects their thinking, feelings, etc. In this article, we will predict the personality of a user based on the data from their social media handle.
Outline of this Article
- Introduction to personality predictions and its methods
- Current methods to predict personality.
- Creating our own personality prediction model
- Results
- Limitations
- Conclusions
What is Personality Prediction?
Every person has a different personality, personality affects a person’s choice in career, decision making. Earlier therapists used questionnaires to predict personalities for example the big five personality questionnaire given in the figure below (figure 1). Person will answer all the questions in this questionnaire ranging from 1 to 5 and the therapist will personally calculate the score of this questionnaire and tell the personality of the person.

But the method is unreliable since the person can fake the answers in this test. Hence we use the person’s Twitter account where people are more open about their opinions and BERT which is an open-source machine learning framework for natural language processing.
Current Methods to predict Personality
There are two personality models : MBTI model and OCEAN model or Big Five Model
MBTI (Myers Briggs Type Indicator)
Myers Briggs Type Indicator is a self-report inventory designed to predict a person’s personality type, strengths, and preferences developed by Isabel Myers and her mother. MBTI inventory is today’s most widely used psychological instrument in the world. People are identified as having one out of 16 personality types. The goal of MBTI is simply to understand us better. No personality type is better than others. MBTI model consists of 2 attitudes every 4 psychological function which consists of Sensing (S) versus Intuition (N), Judging (J) versus Perceiving (P), Extraversion (E) versus Introversion (I), and Thinking (T) versus Feeling (F) totaling to 16 different personality combinations as given in the figure 2.

OCEAN Model
it reveals semantic associations: some words used to describe aspects of personality are often applied to the same person. For example, someone described as conscientious is more likely to be described as “always prepared” rather than “messy”. These associations suggest five broad dimensions used in common language to describe the human personality, temperament and psyche.
The OCEAN model consists of 5 parameters which are
- Openness to experience (inventive/curious vs. consistent/cautious)
- Conscientiousness (efficient/organized vs. extravagant/careless)
- Extraversion (outgoing/energetic vs. solitary/reserved)
- Agreeableness (friendly/compassionate vs. critical/rational)
- Neuroticism (sensitive/nervous vs. resilient/confident)
Predicting personality using N.L.P
There is a significant amount of work done in automatizing personality prediction among the researchers in Natural Language Processing (NLP) and Social Science domain over the world. Most of the studies are based on The BIG Five or MBTI personality model. Ms. Kavita Agarwal in their research paper “Analysis of Human Traits Using Machine Learning ” published at IJCRT,2021 stated that their design was based on a traditional machine learning model, where they designed a website to collect information from users in a question-answer-based system. They used a labeled dataset mbti_1 from Kaggle. Their preprocessing consists of stopword removal, stemming, lemmatization, and TF-IDF vectorizer, and the model is trained using XGboost which is a decision tree-based ensemble machine learning algorithm to predict the final personality traits. We will use the similar Kaggle dataset to first train our NLP model and then we can use the model on real-life Twitter users' tweets. We will use BERT as our language model.
Transformers
Before understanding the BERT model, we need to understand the transformer model in NLP. Sequence-to-Sequence (or Seq2Seq) is a neural network that converts a given sequence of elements, such as word order in a sentence, into another sequence.
The Seq2Seq model is excellent in translation, where the sequence of words in one language is converted into a sequence of words in another language. A popular choice for this type of model is models based on Long-Short-Term-Memory (LSTM). With sequential-based data, LSTM modules can give meaning to a series while remembering the parts they find important.
Seq2Seq models contain encoder and Decoder. The Encoder takes a sequence of inputs and maps them to a higher resolution (n-dimensional vector). That invisible vector is inserted into the Decoder which converts it into an output sequence. Output sequence can be in another language, symbols, input copy, etc.
Encoder and decoder act as human translators who can speak only two languages. Their first languages differ and the second language an imaginary one they have in common
To translate the First language into a second language, the encoder converts the first language into the imaginary language and since the decoder can read that imaginary language, it can now translate the first language into the second language. To be fluent in understanding the imaginary language the encoder and decoder need to be trained with a lot of examples.
Attention — The Attention mechanism looks at an input sequence and decides which parts of the sequence are important.
A Transformer uses a single attention — mechanism. A transformer is an architecture for transforming one sequence into another with help of an encoder and decoder but it does not imply any recurrent network. Transformer differentially weights the significance of each part of the input data.
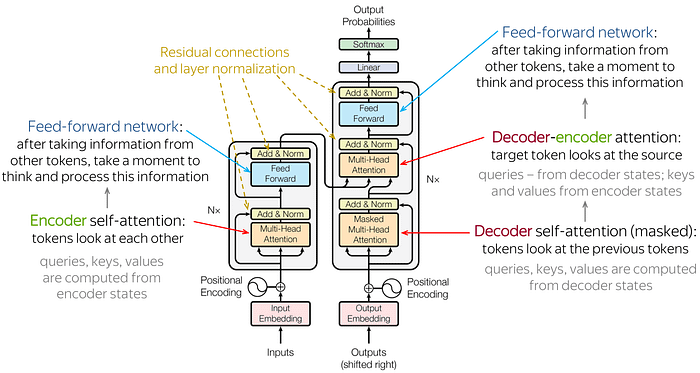
The Encoder is on the left and the Decoder is on the right. Both the Encoder and the Decoder are made up of modules that can be stacked over several times, which Nx describes in the picture. We note that the modules consist mainly of Multi-Head attention layers and Feed Forward. Input and output (target sentences) are first inserted into the n-dimensional space as we cannot use the character unit directly.
One small but important part of the model is the local code of different names. Since we do not have repetitive networks that can remember how sequences are inserted into a model, we need to somehow assign each name/ component to our sequence a related location as the sequence depends on the order of its elements. These fields are added to the embedded representation (n-dimensional vector) of each word.
BERT
BERT is an open source learning framework for natural language processing (NLP). BERT is designed to help computers understand the meaning of an unfamiliar language in a text by using the surrounding text to discover the context. The BERT framework was pre-trained using text from Wikipedia and could be optimized with question and answer data sets.
BERT, representing Bidirectional Encoder Representations from Transformers, is based on Transformers, an in-depth learning model in which everything out there is connected to every input, and weights are calculated randomly based on their connection. In Natural Language Processing, this process is called attention. Bert is a non-sequential type transformer which makes it able to read statements from both direction unlike sequential(seq-seq) models. This concept is called bidirectionality. BERT is pre-trained on two different NLP tasks: Next Sentence Prediction and Masked Language Modeling. The objective of Next Sentence Prediction training is to have the program predict whether two given sentences have a logical, sequential connection or whether their relationship is simply random. The objective of Masked Language Model (MLM) training is to hide a word in a sentence and then have the program predict what word has been hidden based on the hidden word’s context.
So now that we understand the theoretical part of our prediction model, let’s dive into the technical part. We will no predict personality , for that we will use TensorFlow and BERT as our model.
Let’s take a look at our dataset. In the below figure we can see the dataset has 2 columns which consist of type of personality and text data. Our dataset consists of more than 8000 plus text data with personality type.
The first process is to preprocess our data, Our data consists of emojis, punctuation, which are not necessary for training our Natural Language Model. The below code snippet is for preprocessing the text data.
The second step is setting the axis for our BERT-based model, here we will have 4 axes since we have the basic 4 types in the MBTI model. The code snippet for the same is given in the below figure.
Machines do not understand text data, so we need to convert the text data in form of numerical data through which the machine can calculate the similarities between different text data. To do that we use the numpy library in python and use the numpy array encoding method. Which process our text to input in the BertTokenizer.
Finally, we will be training our pre-trained NLP BERT model on our dataset. The pre-trained language model BERT was used and trained with the dataset. The dataset was split into 76%, 12%, and 12 % as a training set, validation set, and test set respectively. We will train our model for 7 epochs with a batch size of 32. We will use the Keras library to calculate the loss of our model on our training dataset for that we use the binary cross-entropy.
Now that we have trained the model using BERT, let’s take a short look at extracting twitter data. To extract Twitter data we use tweepy python library, as shown in the below figure we used tweepy to extract twitter text data of Virat Kohli.
Results
The BERT model which is used in this method gives an accuracy of 75% on the test dataset with an Area Under the Curve of 0.749 after 7 epochs.
Conclusion
Suman Maloji research paper “Big Five Personality Prediction from Social Media Data using Machine Learning ” published in IJEAT,2020 is based on machine learning algorithms performed on the Twitter dataset. They used 4 classic algorithms namely Support Vector Machine (SVM),Logistic Regression, Naive Bayes classifier, and Random Forest algorithm. The personality prediction was based on the OCEAN model. After comparing 4 machine learning algorithms, it is seen that SVM has an accuracy of 58%.
Jennifer Golbeck research paper “Predicting Personality from Twitter” published in IEEE in 2011 used the MyPersonality dataset, which consists of 250 users with a total of 9917 statuses. This dataset collected data through the Facebook app in 2007. Using the profile data as a feature set, they were able to train two machine learning algorithms — ZeroR and Gaussian Processes — to predict scores on each of the five personality traits to within 11% — 18% of their actual value
This article presents our deep learning solution for Personality Prediction using social media data with the help of natural language processing pre-trained model BERT which is the best performing approach on the dataset and tasks across all evaluation metrics
Limitations
If the user has a lesser number of text data in his tweets, the model will not be able to output the correct personality type since text data will be less.
